
This work was a joint project done together with Maitreya Grün, Leo Höppel, Mykyta Ielansky, and Sebastian Zapletal.
Introduction
The fighting video game Mortal Kombat 3 is a classic Atari Game and was first released into arcades in the 1990s. Mastering this 1 vs. 1 fighting game requires skill, tactics and strategy of players. But why bother investing endless hours to acquire these skills when you can also train an AI agent to exceed in this game and to beat even human world champions?
In this post, I try to explain how we built and trained an agent to play Mortal Kombat 3 and while this agent did not actually manage to beat human world champions, it at least managed to consistently beat the game’s built-in AI on “novice” difficulty. Yes I know, not a world revolutionizing break through but better than nothing, right?
Reinforcement learning
Reinforcement learning is a branch of machine learning concerned with optimising an agent to interact with an enviroment such that it maximises a received reward and has gained a lot of public attention in recent years. Especially due to the work of Google’s DeepMind, who used reinforcement learning to teach computers to beat the best human players in games such as chess, Go or StarCraft.
As shown in the figure below, in reinforcement learning, an agent performs an action in an environment, thereby changes the state of the enviroment and then receives a reward (or punishment) for this action. In this manner, the agent ‘learns’ which actions give better rewards compared to others.
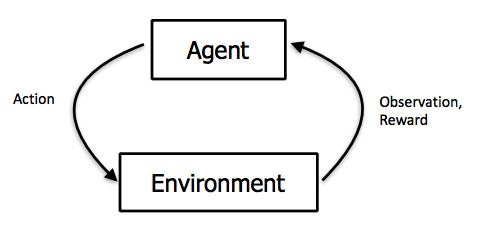
So, unlike supervised learning, the agent, i.e., the model, in reinforcement learning has no specific given target during training that it tries to predict or reproduce. In this sense, we do not tell the agent directly what it has to do. Instead, we let it interact with the enviroment in any way it likes and then afterwards tell it which actions were good and which were bad.
The action-and-reward nature of a fighting game such as Mortal Kombat 3 makes it a perfect candidate for reinforcement learning. While there are many algorithms and architectures that fall under the umbrella of reinforcement learning, we will here only briefly discuss the approaches that we used, which are called Imitation learning and Proximal Policy Optimization (PPO). But first, we need an enviroment to play the game in…
OpenAI’s Gym
OpenAI’s Gym is an open-source library that provides an easy-to-use interface to apply reinforcement learning to thousands of video games. In particular, the extension Gym Retro features, among several other classic video games, an interface to Mortal Kombat 3 that we used to apply reinforcement learning to this game.
Each environment in Gym Retro includes a subset of actions which represent various user inputs on the original console for the game. In the case of Mortal Kombat, there are the 10 actions low punch, low kick, high punch, high kick, left, right, up, down, block, and run. There is also a universal step function that inputs a button choice to the environment, and returns, among other things, a reward. The reward in Mortal Kombat is positive if the agent’s action resulted in damage on the opponent, and negative if the action resulted in damage to the agent. Each state of the enviroment for Mortal Kombat is encoded in form of four frames, information about the health status of both players and the number of matches won (each round consists of 2 matches).
Preprocessing
The main input of our model are the frames that encode the current state of the enviroment. We could theoretically directly feed the four raw images that are given by the environment into our model. However, doing some preprocessing first, allows us on the one hand to speed up training and on the other hand also improves performance. To this end, we first of all crop away the top part of the image in order to remove the health bars, so that the agent can better ‘concentrate’ on the players and does not get distracted. We also downsample the images, convert them to grayscale and, in order to better detect motions, compute the frame residuals, i.e., the differences of two consecutive frames.
The following figure shows the difference between the four raw frames and our preprocessed frames (the first three pictures in the second row are the frame residuals and the last picture is the last frame).

Model architecture
The three preprocessed frame residuals are fed into a 5 layer convolutional neural network (CNN). Each layer in this CNN is followed by a ReLU activation, batch normalization and average pooling. In the end, this yields a total of 32 features maps, each of size 8 x 4. These 32*8*4 = 1024 values are then passed through a final linear layer to give 256 features.
Similarly, also the last frame is passed through a 5 layer CNN with the same architecture as the one described above followed by a final linear layer to also give 256 features.
Additionally to the preprocessed frames, we also provide the agent’s last action as input. This shall help the agent to learn combos, which are specific combinations of buttons pressed and result in more damage. The last action, in form of a one-hot encoded vector, is passed through a small recurrent neural network (RNN) consisting of two gated recurrent unit (GRU) layers, which returns a vector consisting of 512 features.
Then, these three different feature vectors are concatenated to give a feature vector of size 1024, which is then passed through a 3 layer fully connected network with tanh activations to give a total of 10 action scores.
The following image gives an overview over our model architecture.
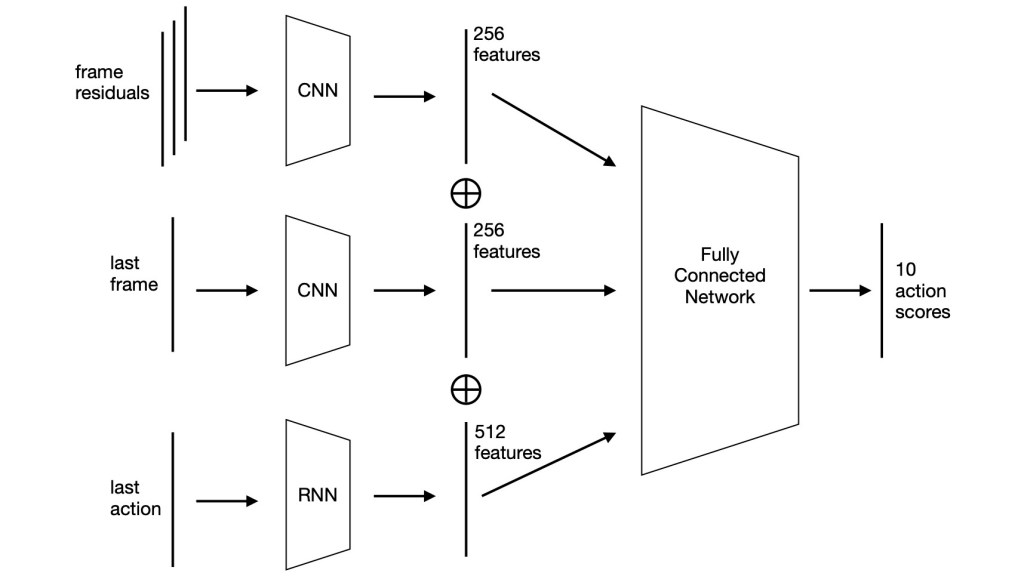
Finally, the action with the highest action score is chosen and executed.
Training
To get a descent initialisation of our agent, we started our training with Imitation learning. Imitation learning basically translates reinforcement learning into a supervised setting, where the agent tries to learn, and then imitate, the behaviour of some expert. In our case, we provided several games that we played ‘by hand’ and in which we constantly spammed combos against an opponent that was not moving at all. The goal of this initial stage of training was to teach the agent how to apply combos, which indeed worked quite well.
Once we had an agent that could regularly apply combos, we switched our training style and let the agent play against several different opponents that all basically executed random actions but with a slight bias either to attacking or defending. During these games, we used PPO to train our agent.
Proximal Policy Optimization (PPO) is a combination of an Actor-Critic model with a policy gradient approach. The main idea of an Actor-Critic algorithm is to split the model into two parts: the actor, which computes an action based on the game state, and the critic, which evaluates this action. As time passes, both, the actor and the critic, get better at their jobs, and help each other improve. The policy of an agent basically determines which action to choose in which state of the environment. The objective of policy gradient is to find a policy that maximises the reward returned from the enivornment by doing some form of gradient descent. In PPO, a policy gradient approach is used that relies on a trust region technique that penalizes the difference between the new and old policy, in order to allow for larger changes and thus faster learning, without as much risk of overshooting the optima and getting bad results. For more information on PPO, please check out this Medium post.
Results
After training this agent for about half a day, we were able to achieve reasonably good results. Namely, the agent was able to consistently beat the game’s built-in AI on “novice” difficulty. What is particularly interesting is that it manages to beat this opponent although it was never trained to play against it. Here are some screenshots from an exemplary fight – our agent is Nightwolf (in the blue shorts). To see the full video, click here.








